Supplemental material 6
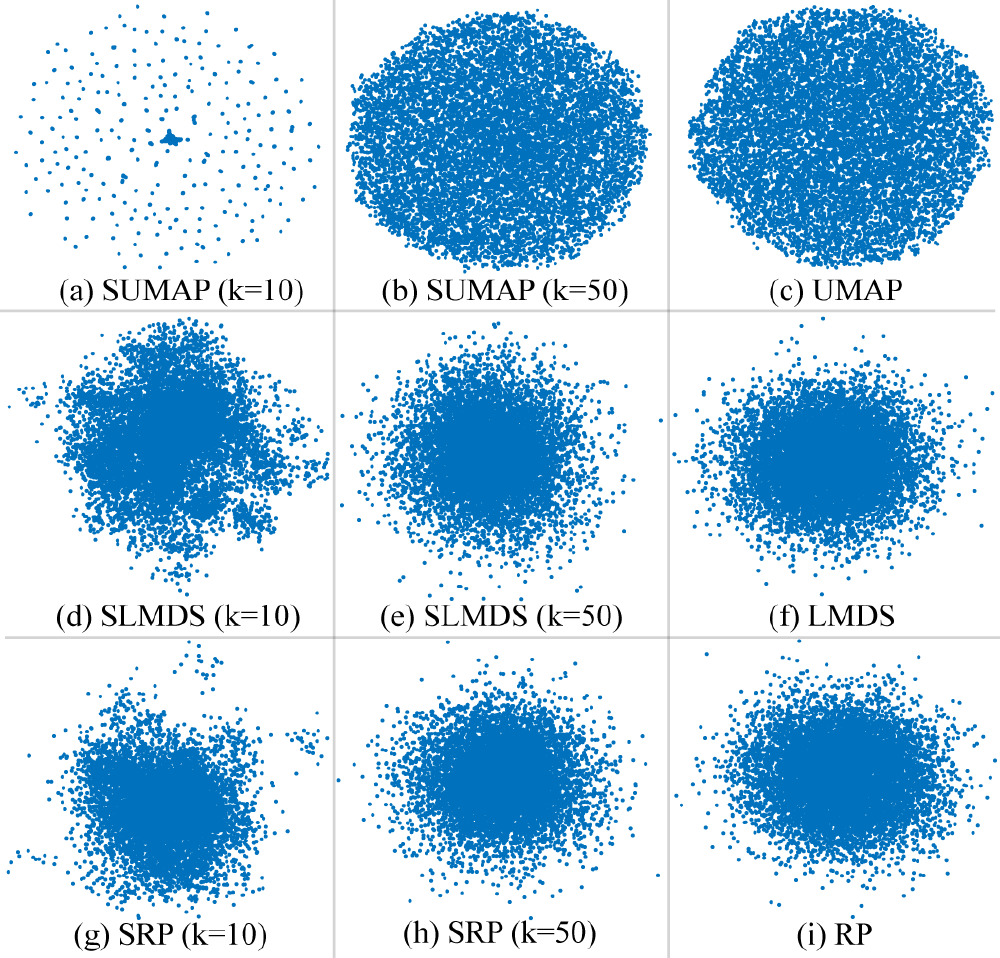
Results of DR and SDR with varying k-values for sharpening. The synthetic data set consists of 10K randomly generated observations in 20D. Note that (a), (d), and (g) show oversegmented clusters using k=10, while (b), (e), and (h) show a single cluster using k=50 for LGC.